Big Data Workflow Using Tall Arrays and Datastores
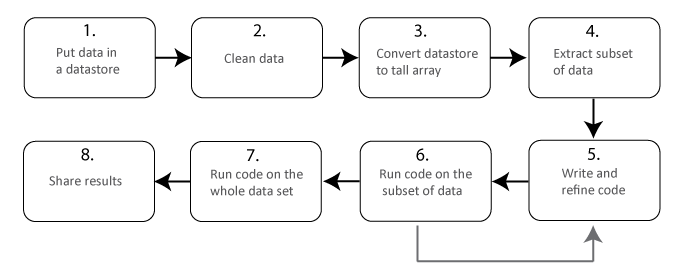
The illustration shows a typical workflow that uses tall arrays to analyze a large data set. In this workflow, you analyze a small subset of the data before scaling up to analyze the entire data set. Parallel computing can help you scale up from steps six to seven. That is, after checking that your code works on the small data set, run it on the whole data set. You can use MATLAB® to enhance this workflow.
| Problem | Solution | Required Products | More Information |
|---|---|---|---|
| Is your data too big? | To work with out-of-memory data with any number of rows, use tall arrays. This workflow is well suited to data analytics and machine learning. | MATLAB | |
Use tall arrays in parallel on your local machine. | MATLAB Parallel Computing Toolbox™ | ||
Use tall arrays in parallel on your cluster. | MATLAB Parallel Computing Toolbox MATLAB Parallel Server™ | To use tall arrays on a Hadoop cluster, see Use Tall Arrays on a Spark Cluster For all other types of cluster, use a non-local cluster profile to set up a parallel pool. For an example, see Use Tall Arrays on a Parallel Pool | |
If your data is large in multiple dimensions, use
| MATLAB Parallel Computing Toolbox MATLAB Parallel Server |
Running Tall Arrays in Parallel
Parallel Computing Toolbox can immediately speed up your tall array calculations by using the full processing power of multicore computers to execute applications with a parallel pool of workers. If you already have Parallel Computing Toolbox installed, then you probably do not need to do anything special to take advantage of these capabilities. For more information about using tall arrays with Parallel Computing Toolbox, see Use Tall Arrays on a Parallel Pool.
Use mapreducer to Control Where Your Code Runs
When you execute tall arrays, the default execution environment uses either the
local MATLAB session, or a local parallel
pool if you have Parallel Computing Toolbox. The default pool uses local workers, typically one worker for each
core in your machine. Use the mapreducer function to change the execution environment of tall
arrays to use a different cluster.
One of the benefits of developing your algorithms with tall arrays is that you
only need to write the code once. You can develop your code locally, then use
mapreducer to scale up and take advantage of the
capabilities offered by Parallel Computing Toolbox and MATLAB
Parallel Server.
See Also
gather | tall | datastore | mapreducer
Related Examples
- Use Tall Arrays on a Parallel Pool
- Use Tall Arrays on a Spark Cluster
- Tall Arrays for Out-of-Memory Data
- Choose a Parallel Computing Solution
More About
You can also select a web site from the following list:
Americas
- América Latina (Español)
- Canada (English)
- United States (English)
Europe
- Belgium (English)
- Denmark (English)
- Deutschland (Deutsch)
- España (Español)
- Finland (English)
- France (Français)
- Ireland (English)
- Italia (Italiano)
- Luxembourg (English)
- Netherlands (English)
- Norway (English)
- Österreich (Deutsch)
- Portugal (English)
- Sweden (English)
- Switzerland
- United Kingdom (English)